We present several annotated instances of human subjects from the proposed HAPS 2.0 Dataset (overall and single), showcasing a variety of well-aligned motions, movements, and interactions.

University of Washington
University of Washington
University of Washington
University of Washington
University of Washington
Galbot
University of Washington
University of Mannheim
Carnegie Mellon University
Microsoft Research
Carnegie Mellon University
*Equal contribution. Work done during internship at UW., †Corresponding author.
Vision-and-Language Navigation (VLN) has been studied mainly in either discrete or continuous settings, with little attention to dynamic, crowded environments. We present HA-VLN 2.0, a unified benchmark introducing explicit social-awareness constraints. Our contributions are: (i) a standardized task and metrics capturing both goal accuracy and personal-space adherence; (ii) HAPS 2.0 dataset and simulators modeling multi-human interactions, outdoor contexts, and finer language–motion alignment; (iii) benchmarks on 16,844 socially grounded instructions, revealing sharp performance drops of leading agents under human dynamics and partial observability; and (iv) real-world robot experiments validating sim-to-real transfer, with an open leaderboard enabling transparent comparison. Results show that explicit social modeling improves navigation robustness and reduces collisions, underscoring the necessity of human-centric approaches. By releasing datasets, simulators, baselines, and protocols, HA-VLN 2.0 provides a strong foundation for safe, socially responsible navigation research.
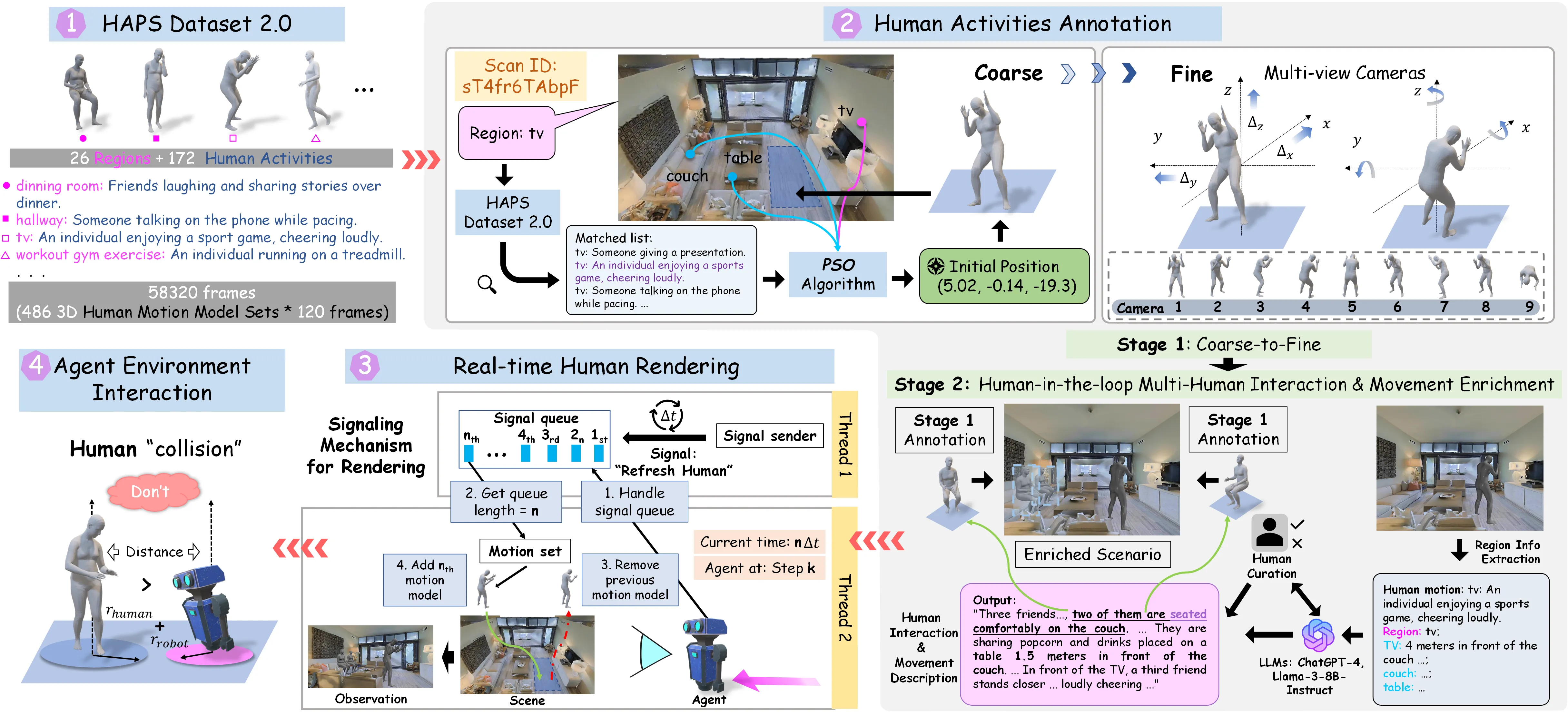
Overall View of Nine Annotated Scenarios from HA-VLN Simulator (90 scans in total)

Single Humans with Movements (910 humans in total)
Visualization results of agent's trajectory
@misc{dong2025havlnbenchmarkhumanawarenavigation,
title={HA-VLN: A Benchmark for Human-Aware Navigation in Discrete-Continuous Environments with Dynamic Multi-Human Interactions, Real-World Validation, and an Open Leaderboard},
author={Yifei Dong and Fengyi Wu and Qi He and Heng Li and Minghan Li and Zebang Cheng and Yuxuan Zhou and Jingdong Sun and Qi Dai and Zhi-Qi Cheng and Alexander G Hauptmann},
year={2025},
eprint={2503.14229},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2503.14229},
}